Все знают одну особенность программистов – мы всегда хотим использовать лучшие инструменты, иметь самое быстрое железо и прорабатывать архитектуру так, чтобы быть готовыми вырасти в over900 раз за ночь. А если это еще и что-то новенькое, то бизнес вполне может получить под капотом MongoDB+Qt для задачи десктопного калькулятора.
Но давайте взглянем на это с точки зрения бизнеса – в каком случае действительно целесообразно использовать технологии высокой нагрузки и какие они вообще бывают?
Понятно, что любой бизнес на вопрос «Хотите получать большую отказоустойчивость?» ответит «Конечно!». Нюансы как всегда под капотом, ведь правильный ответ «Конечно, если это будет автоматически и бесплатно». Но, как понимаете, это не так?
Архитектура + поддержка решения на ваших серверах
Если подойти структурно к анализу технических средств для высоконагруженных систем, то, пожалуй, можно разделить их на 4 непересекающихся класса:
- Базы данных
В базовой конфигурации вполне подходят PostgreSQL, MySQL, MS SQL. Если хочется эдакого, то конечно можете поставить себе Percona или любую NoSQL базу, но обратите внимание на слово «хочется»: это точно то, что необходимо бизнесу?
- Очереди и шины данных
Тут все просто – есть быстродействие, а есть производительность, и чтобы ее обеспечить, инженеры уже давно придумали механизм очередей, где в прозрачный плоский список встают все запросы, а потом разгребаются отдельным процессом. Тут лидеры – это Kafka, RabbitMQ, IBM MQ, Amazon SQS. Хороши все четыре.
- Системное ПО + сервисное ПО
Это точно не то, с чего нужно начинать, но в целом, конечно, такого ПО достаточно от систем развертывания в контейнерах для быстрого disaster recovery до отдельных программных мониторингов на Prometheus + Graphana.
- «Правильные» языки программирования
Сейчас с этим с одной стороны проще, с другой есть много модного. Просто помните две вещи:
- Обычно, если у языка программирования или технологии версия 0.Х, то стоит подождать внедрением в реальном бизнесе (хотя есть исключения, если хотите в этом разбираться)
- Есть анекдот про Джава: «Тук-тук… кто там?… … очень долгая пауза … Джава!» (уже не так актуально, как 10 лет назад, но осадочек остался)
Для примера посмотрите, как мы сделали архитектуру сервиса Loyalty Creatio, а в следующем разделе увидим, что может такая на первый взгляд легкая архитектура.

Важно, что благодаря такой схеме мы предоставляем возможность не только SaaS в облаке, но и установку на сервера клиента.
Минимальное железо + типовая постоянная нагрузка
Давайте начнем с простого железа – это будет типовой компьютер НЕ в серверной стойке и с ограниченным объемом памяти.
| Параметр | Значение |
| Процессор | Intel Core i3-6100 3.70 GHz (CPU: 6) |
| Память | 3 Gb |
| Диск | 20 Gb |
Также обозначим исходные параметры базы данных, на которой будет проводиться тест.
| Параметр | Значение |
| Количество клиентов | 546 |
| Количество продуктов | 30007 |
| Количество покупок | 53 |
| Количество событий в базе | 10 |
| Количество начислений и списаний | 558 |
| Количество активных правил расчета | 3 |
| Количество правил | 13 |
| Количество пользователей | 10 |
Посмотрим, как на таких исходных данных работает вызов метода calculate для сложного чека, в котором есть 10 продуктов и должны сработать 3 правила одновременно: одно на сумму чека, одно на товар в чеке и одно на комплект.
Поехали!

На графике видно, что время ответа на все запросы при такой нагрузке не более 60 миллисекунд.
Собственно, на этом можно было бы закончить, потому что такая нагрузка и скорость ответа с запасом удовлетворяет потребности 97% бизнесов даже на указанном железе. Я имею в виду, что, если вы построили бизнес, где каждую секунду создается заказ на отгрузку – вы один из чемпионов и обгоняете, например, Перекресток, у которого до 16 запросов в минуту.
Но давайте посмотрим, что будет, если мы увеличим нагрузку до 5, 10 и 15 запросов в секунду.



На графике видно, что для нагрузки 15 запросов в секунду время ответа на 90% запросов не превышает 300 мс.
Если мы попробуем радикально увеличить количество запросов, то система естественно будет продолжать работать, проверено в боевых условиях на распродажах с огромными пиками.

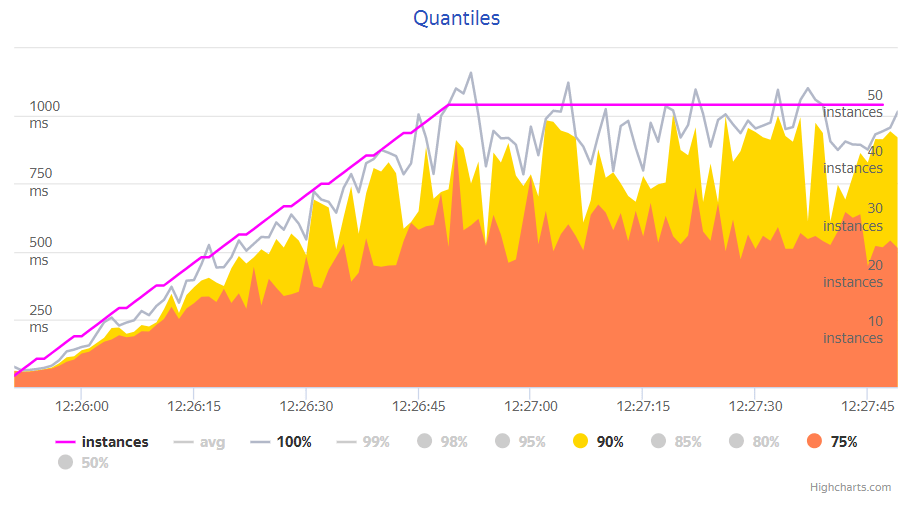
Итог – процессинг при памяти 3 Gb держит нагрузку в 50 запросов/секунду и выдает ответ с расчетом чека в течение 0,9с.
Еще раз отмечу – что это НЕ ферма application серверов и серверов баз данных, не выделенная корзинка дисков, вообще не серверное железо, а сам сервис и база данных находятся на 1 машине.
Выводы
Подведем итоги нашего тестирования:
- Highload нужен не всем. Скорее всего необходимого результата эффективней с точки зрения бизнеса достичь оптимизацией текущих процессов, а не устранением фатального недостатка архитектуры.
- Если действительно нужна высокая нагрузка, то это в первую очередь вопрос архитектуры, а не железа стоимостью крыла от Боинга.
- Для устранения рисков используйте проверенные промышленные решения
- Не стесняйтесь общаться напрямую с теми, кто уже использует решение. Практически любой успешный бизнес готов делиться лучшими практиками. Конечно, можно и модный велосипед изобретать на Мemcached / Cassandra / Hadoop / MapReduce (нужное подчеркнуть), но это в том случае, если вы готовы брать на себя риски за сроки и факапы. Ничего плохого в этом нет, если вы осознаете, что это ваше осознанное бизнес-решение.
Вот, собственно, и все. ? Бонус всем, кто дочитал – могу показать в онлайн нагрузку под ваши параметры (сгенерировать нужное количество клиентов, покупок, пользовательских событий) – welcome!
Саша Свистунов, технический директор ПТ